您现在的位置是:主页 > 行业新闻 >
AI 看唇语,在嘈杂场景的语音识别准确率高达75%
人们通过聆听和观察说话者的嘴唇动作来感知言语。那么,AI 也可以吗?

 AV-HuBERT
AV-HuBERTMeta 并不是第一个将人工智能应用于读唇语问题的公司。2016年,牛津大学的研究人员创建了一个系统,该系统在某些测试中的准确率几乎是经验丰富的唇读者的两倍,并且可以实时地处理视频。2017年,Alphabet 旗下的 DeepMind 在数千小时的电视节目中训练了一个系统,在测试集上可以正确翻译约 50%的单词而没有错误,远高于人类专家的 12.4%。但是牛津大学和 DeepMind 的模型,与许多后续的唇读模型一样,在它们可以识别的词汇范围内受到限制。这些模型还需要与转录本配对的数据集才能进行训练,而且它们无法处理视频中任何扬声器的音频。有点独特的是, AV-HuBERT 利用了无监督或自我监督的学习。通过监督学习,像 DeepMind 这样的算法在标记的示例数据上进行训练,直到它们可以检测到示例和特定输出之间的潜在关系。例如,系统可能会被训练在显示柯基的图片时写出单词「dog」。然而,AV-HuBERT 自学对未标记的数据进行分类,处理数据以从其固有结构中学习。
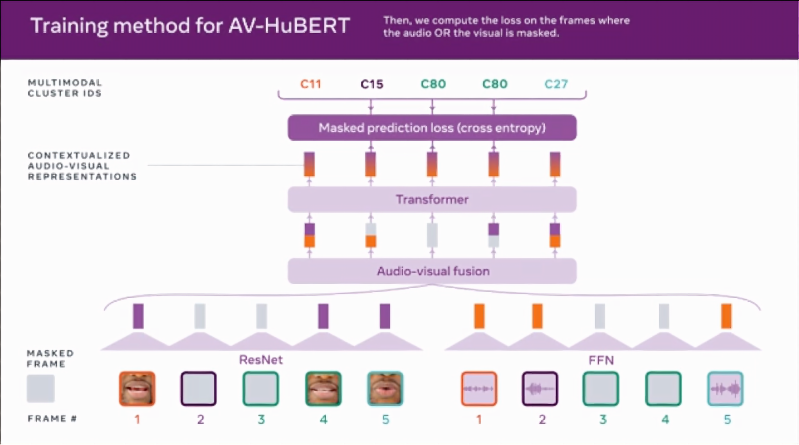 AV-HuBERT 也是多模态的,因为它通过一系列的音频和唇部动作提示来学习感知语言。通过结合说话过程中嘴唇和牙齿的运动等线索以及听觉信息,AV-HuBERT 可以捕捉这两种数据类型之间的细微关联。最初的 AV-HuBERT 模型在 30 小时的 TED Talk 视频上进行了训练,大大少于之前最先进模型的 31,000 小时的训练时间。但是,尽管在较少的数据上进行了训练,AV-HuBERT 的单词错误率 (WER)(衡量语音识别性能的指标)在可以看到但听不到说话者的情况下略好于旧模型的 33.6%,前者为 32.5%。(WER 的计算方法是将错误识别的单词数除以总单词数;32.5% 转化为大约每 30 个单词出现一个错误。)在 433 小时的 TED 演讲训练进一步将 AV-HuBERT 的 WER 降低到 28.6%。一旦 AV-HuBERT 很好地了解了数据之间的结构和相关性,研究人员就能够在未标记的数据上进一步训练它。上传到 YouTube 的 2,442 小时名人英语视频,这不仅使 WER 下降到 26.9%,而且 Meta 表示,它表明只需要少量标记数据来训练特定应用程序(例如,当多人同时说话时)或不同语言的框架。事实上,Meta 声称当背景中播放响亮的音乐或噪音时,AV-HuBERT 在识别一个人的语音方面比纯音频模型好约 50%,当语音和背景噪音同样响亮时,AV-HuBERT 的 WER 为 3.2%,而之前的最佳多模式模型为 25.5%。
AV-HuBERT 也是多模态的,因为它通过一系列的音频和唇部动作提示来学习感知语言。通过结合说话过程中嘴唇和牙齿的运动等线索以及听觉信息,AV-HuBERT 可以捕捉这两种数据类型之间的细微关联。最初的 AV-HuBERT 模型在 30 小时的 TED Talk 视频上进行了训练,大大少于之前最先进模型的 31,000 小时的训练时间。但是,尽管在较少的数据上进行了训练,AV-HuBERT 的单词错误率 (WER)(衡量语音识别性能的指标)在可以看到但听不到说话者的情况下略好于旧模型的 33.6%,前者为 32.5%。(WER 的计算方法是将错误识别的单词数除以总单词数;32.5% 转化为大约每 30 个单词出现一个错误。)在 433 小时的 TED 演讲训练进一步将 AV-HuBERT 的 WER 降低到 28.6%。一旦 AV-HuBERT 很好地了解了数据之间的结构和相关性,研究人员就能够在未标记的数据上进一步训练它。上传到 YouTube 的 2,442 小时名人英语视频,这不仅使 WER 下降到 26.9%,而且 Meta 表示,它表明只需要少量标记数据来训练特定应用程序(例如,当多人同时说话时)或不同语言的框架。事实上,Meta 声称当背景中播放响亮的音乐或噪音时,AV-HuBERT 在识别一个人的语音方面比纯音频模型好约 50%,当语音和背景噪音同样响亮时,AV-HuBERT 的 WER 为 3.2%,而之前的最佳多模式模型为 25.5%。 
潜在的缺点
在许多方面来看,AV-HuBERT 象征着 Meta 在用于复杂任务的无监督、多模式技术方面不断增长的投资。Meta 表示 AV-HuBERT 可以为开发“低资源”语言的对话模型开辟可能性。该公司建议,AV-HuBERT 还可用于为有语言障碍的人创建语音识别系统,以及检测深度伪造和为虚拟现实化身生成逼真的嘴唇运动。在各方面数据上,新方法的变现着实很精彩,但也有学者有一些担忧。其中,华盛顿大学的人工智能伦理学专家Os Keye就提到,对于因患有唐氏综合征、中风等疾病而导致面部瘫痪的人群,依赖读唇的语音识别还有意义吗?在微软和卡内基梅隆大学的一篇论文中,提出了人工智能公平性研究路线图,指出类似于 AV-HuBERT 的面部分析系统的某些方面可能不适用于患有唐氏综合症、软骨发育不全(损害骨骼生长)和“导致特征性面部差异的其他条件”等。Mohamed 强调 AV-HuBERT 只关注唇部区域来捕捉唇部运动,而不是整个面部。他补充说,与大多数 AI 模型类似,AV-HuBERT 的性能将“与训练数据中不同人群的代表性样本数量成正比”。“为了评估我们的方法,我们使用了公开可用的 LRS3 数据集,该数据集由牛津大学研究人员于 2018 年公开提供的 TED Talk 视频组成。由于该数据集不代表残疾说话者,因此我们没有预期性能下降的特定百分比,”Mohamed 说。Meta 表示,它将“继续在背景噪声和说话者重叠很常见的日常场景中进行基准测试和开发改进视听语音识别模型的方法。”
THE END
来源 | AI科技大本营
上一篇:一套弱电智能化施工组织设计
随机图文

华为大单:5亿鹏城云脑Ⅱ平衡计算系统采用单一来源
11月12日,鹏城云脑Ⅱ扩展型信息化工程平衡计算系统单一来源采购审批前公示,预算金额:50599.21万元,拟定单一来源供应商:华为技术有限公司; 项目一 项目名称1:鹏城云脑Ⅱ扩展型信息化工程平衡计算系统 预算金额:50599.21万元 拟采购项目的说明:鹏城云脑Ⅱ扩展型信息化工程平衡计算系统采购项目,将完成《鹏城云脑Ⅱ扩展
项目上真正成功的领导者,会积极帮助团队成员成功
01 全面的自我认知 领导者必须准确地了解自己的优势和劣势。根据美国创新领导力中心的吉恩·莱斯利博士(Dr. Jean Leslie)的说法,一位优秀的领导者在任何时候必须始终清楚地了解六个关键问题:我的优势是什么?我做事的风格是什么?我是谁?我的职责是什么?我能贡献什么?我的人际关系怎么样? 02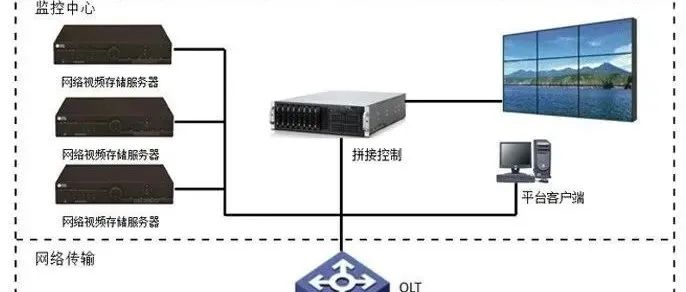
能看懂这几种监控系统架构,大小弱电项目你都能接
大家好。监控系统是我们工作中最常见的子系统。有多少常见的监控系统体系结构?今天,品至安防给您一个总结。如果你掌握了这些系统架构,你就可以拥有市场上所有大小的监控系统。 第一种方法:传统的方法是由网络摄像头+电源+网线 组成。使用综合布线时,电源线和网线应同时敷设。附近的电源也可以是220V AC,以节省电源线。这里不讨论其优缺点。为每个网络摄像头供电。另一条网线将网络数据传输到网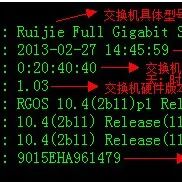
锐捷交换机查看配置的十大命令,品至安防教你不迷路
关于锐捷交换机的使用,一直都有不少朋友问起,因为使用锐捷交换机的朋友越来越多,前几天我们还发布关于锐捷交换机的登陆配置,本期我们来总结下关于链接交换机查看配置命令,这十大命令非常常用。 一、交换机配置信息查看十大命令 1、Ruijie#show version 命令可以查看交换机具体型号、软件版本、硬件
站点信息
- 文章统计: 1437 篇文章
- 微信公众号:扫描二维码,关注我们